传统与深度学习SLAM技术杂谈
这几个月在再次深度学习了SLAM技术后,感觉SLAM技术中无论是传统派还是目前的learning派,本质上都是在回答一个问题:如何在多种传感器中获取到最准确的信息,并基于这些信息进行运动和定位的估计。并在这个基础上得出一个各个传感器的关系,并基于这个关系进行运动和定位的估计。这个过程完全基于运动学,只不过传统SLAM技术是对这个传感器进行一个精确的数学建模,而learningSLAM技术则更加模糊,通过学习传感器的参数,来对传感器进行建模。但是他们无一例外都保持了一个核心:偏导与损失函数,这里我们详细讲述一下。
两代SLAM技术的藕断丝连
我们都知道传统SLAM存在两种技术路线:滤波器与图优化方法。目前的传统SLAM路线中图优化已经压倒了滤波器方法,滤波器方法已经退回到IMU等导航方案发挥余热,因此我们在传统SLAM中主要介绍图优化方法。
图优化为代表的传统SLAM
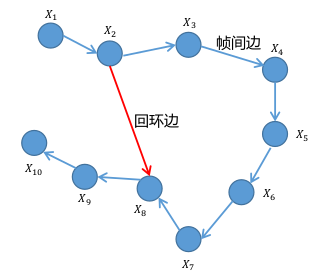
如图所示,这个图中每个节点都对应一个机器位姿,两个节点之间的边表示两个位姿的空间约束(相对位姿关系以及对应方差或线性矩阵)。当然边分为了两种边:回环边和帧间边。回环边会表示两个不同的node出现了相同的环境结果,正是因为有回环检测才会出现误差。而帧间边则表示两个不同的node之间存在运动关系,这个部分可以通过传感器确定,甚至可以借助滤波器理论(IMU与其他传感器的搭配)当然这都是后话了。总之图优化是对节点与回环误差的优化。
不过我们大可以极端一点,我们都知道的是图优化的优化过程是一个迭代过程,他的迭代速度可以说是取决于他的环境采样速度,他的优化公式为
其中损失部分为 ,含义为最小化回环后的各部分加权平方和
这里是实际观测值。
而观测模型,是根据当前状态预测的观测值(在滤波器里我们直接叫他预测值)。
由于 $h_{ij}(.)$ 往往是非线性的,所以这个理就可以看做一个非线性二乘法问题,直接算太痛苦,所以大部分直接用泰勒展开来计算(雅可比矩阵来喽),这里就不详细展开了。
在进行线性化等操作后,构建增量方程,因为你的物体是运动的,所以你需要进行不停增加这个物体的预测等
这里明眼人一眼就能看出来
这玩意就是阶展开后的残差,因为仅仅是一阶展开所以就相当于一个线性方程,这里往往叫做线性化。
回到上面的方程,这是一个关于
$\Delta \mathbf{x}$
的方程,也就是说他是接受迭代的,这也就是他的最终优化目的——在运动中疯狂修正。
那么我们极端的想法就来了,在数学上我们都知道一个极限化,我们医药把这个极限化:我们要把采样的频率无限大,这样他的残差离散化就会无限小直到变成一个连续的方程曲线,正因为从概率角度来看。图优化的目标函数直接来源于最大后验概率估计的概率模型,优化过程是一种加权平均的过程(说到底传统SLAM就是一个加权平均过程),那么他的优化函数就变成了:
看上去没啥太大变化哈,也就是他变成连续的了,但是这就是他的最重要的:在这种极限下,图优化问题就从优化一组离散位姿,转变为优化一个连续时间函数。约束(边)也变成了连续时间上的约束积分。这正是连续时间轨迹优化 或基于样条的SLAM 的思想,目标函数的形式没有本质改变,依然是一个“损失函数,这就是一种奇形怪状的loss函数。
另一个角度看待图优化,我们就需要从他的目的下手了。作为一个迭代过程,它实际上是为了求取最佳权重(信息矩阵),这样看下来他的图的node就是神经网络的参数,边是约束等;优化求解就是使用梯度下降(或高斯-牛顿法)训练网络,最小化总损失。
光怪陆离的learningSLAM
那我们在把目光投向learningSLAM中.损失函数太多了我们就直接用一个应用比较广泛的位姿损失函数作为例子:
这个在传统与深度学习中皆有广泛应用,我们可以观察其中的样式与图优化的十分相似。
由于learnSLAM过于繁多与复杂(而且很多是学术界的成果),这里我们只是去简单讲述他的优化与损失过程。
在learn中我们的优化过程已经是老生常谈的东西了:梯度下降的贤子孝孙与反向传播。这一切有是在loss函数中进行的,这里我们还是需要最大后验概率估计的概率模型去估计此时整体的参数处于的优化位置在哪里,然后SGD或者什么去找到最佳的参数,这个损失函数就是基于公式4等其他公式(也是基于现实的位姿进行的校准)。那我们就可以反过来看公式(3),这个公式在功能上是公式4最期待的结果(反应误差。进行修正),也就是说在衡量误差的过程中,我们的learningSLAM实际上也是对自我迭代出来的位姿与实际位姿的一种更新。
那么他的更新过程呢?很明显这也是一个权重分配的过程,但是权重分配要比传统的SLAM复杂得多,包括各个传感器与雷达摄像头的一种杂糅融合。但是我们在宏观上看待这个部分,草率得把传感器切割开来单独看他的的处理与融合部分,我们会发现:这是一种另类的赋权方法啊,只不过赋权与滤波混杂在一起了(CNN就是去噪赋权滤波一气呵成。也算是深度学习特色了)。即便是这样,有些敏感的人也能感觉到他们的方法论还是如此的相似。整体的路程是如此相像。
两种SLAM最终的分歧
这个很明显,他们的最大的分歧就是对于物理约束的应用层面。即使learn派约束再多也不如传统SLAM直接把运动学迭代公式拍你脸上,把马尔可夫性neta成上帝。他们完全依赖对于世界的物理学建模与环境约束,相信并利用已知的物理方程,并在此基础上构建优化问题,这是一种演绎法,基于原理来推导现实。
但是深度学习不这么想,他雄心勃勃,认为只要方法得当,利用统计学神力,大数原理,自动微分等就能拟合一切得到隐含的物理方程。对于物理方程的显式建模有了一定程度的舍弃,取而代之的隐函数的拟合等方法。
这也解释了为什么传统SLAM永远无法解决corner case,为什么learning上限更高,下限更低——传统SLAM受限于其本征公式的表达缺陷,无法对外部环境进行一个完全的精确的建模,但是由于其环境约束的设定以及其可解释性,下限比learning好的多。但是他没有深度学习的一个好处,就是对外部环境的一个较为全面的非线性优化方法,尽管这个方法有可能会造成更多的噪声,或者长尾分布,或者数据的不均匀性,导致其求解失败效果更差。