VAE学习笔记与感悟
VAE作为AE与扩散模型的承前启后的模型网络,重要性不言而喻。笔者在这里写一个关于VAE的简述来总结一下自己的感悟吧
一,模型构成
一般来说,VAE模型由encoder和decoder构成。前者负责学习,后者负责练习。也就是说VAE通过encoder对输入的信息进行解析变换并学习里面的主要特征(例如图像),在decoder中进行重建并进行图像重构然后将重构的图形与原来的图像比较计算相似度然后反向传播更改参数权重再进行下一步练习。
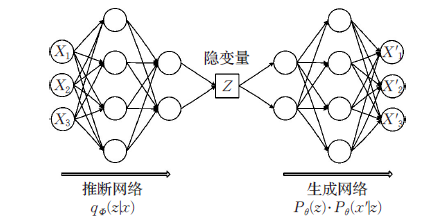
那么他的训练原理是什么呢?
VAE把人脸的各个部分进行独立建模,他引入了一个先验就是各个部分的信息应当符合高斯分布,模型只需要学习最主要的特征就可以了。很明显这样就可以避免很多噪声(你总不能眼睛部位分析出嘴巴的特征吧)。就跟眼睛的大小一样,一般模型会对这些特征进行一个量化,然后指出笑得时候眼睛长什么样,哭的时候眼睛什么样等等等等。而变分自编码器便是用取值的概率分布代替原先的单值来描述对特征的观察的模型,如下图的右边部分所示,经过变分自编码器的编码,每张图片的微笑特征不再是自编码器中的单值而是一个概率分布。
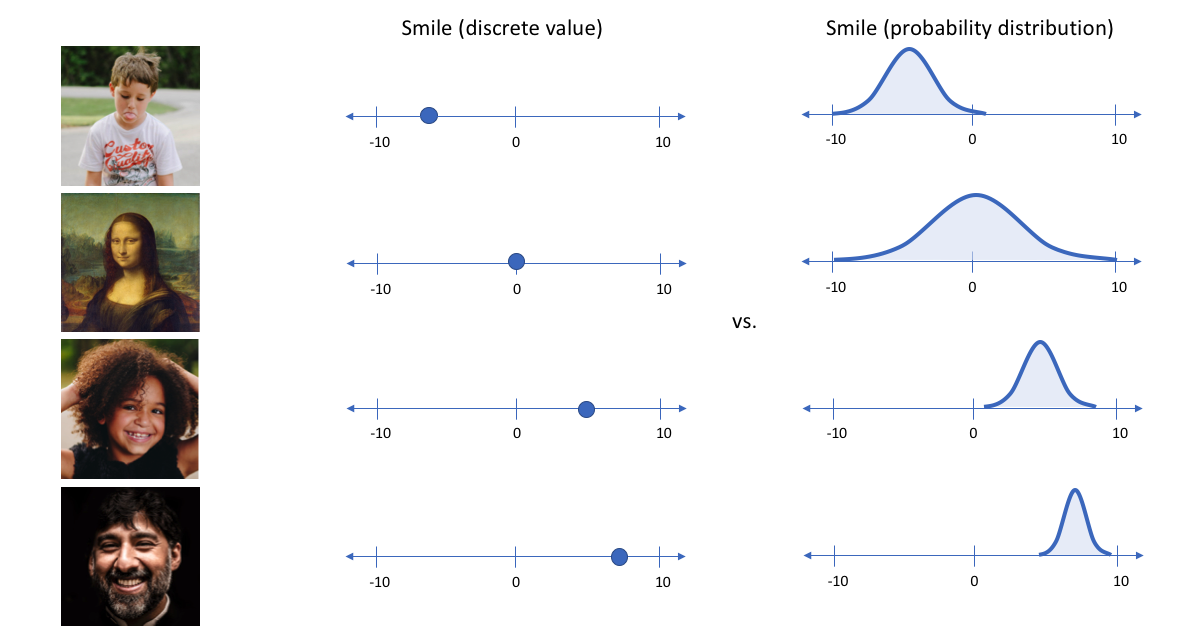
那样我们把这个概率输入到decoder里面去进行重构那就更加符合统计学原理了不是吗?
也就是说我们在隐空间进行了一个处理学习了他们的特征的概率分布(符合高斯分布)然后在进行图像重构等一系列操作。
二,数学原理
先扔出一张图(网上找的)
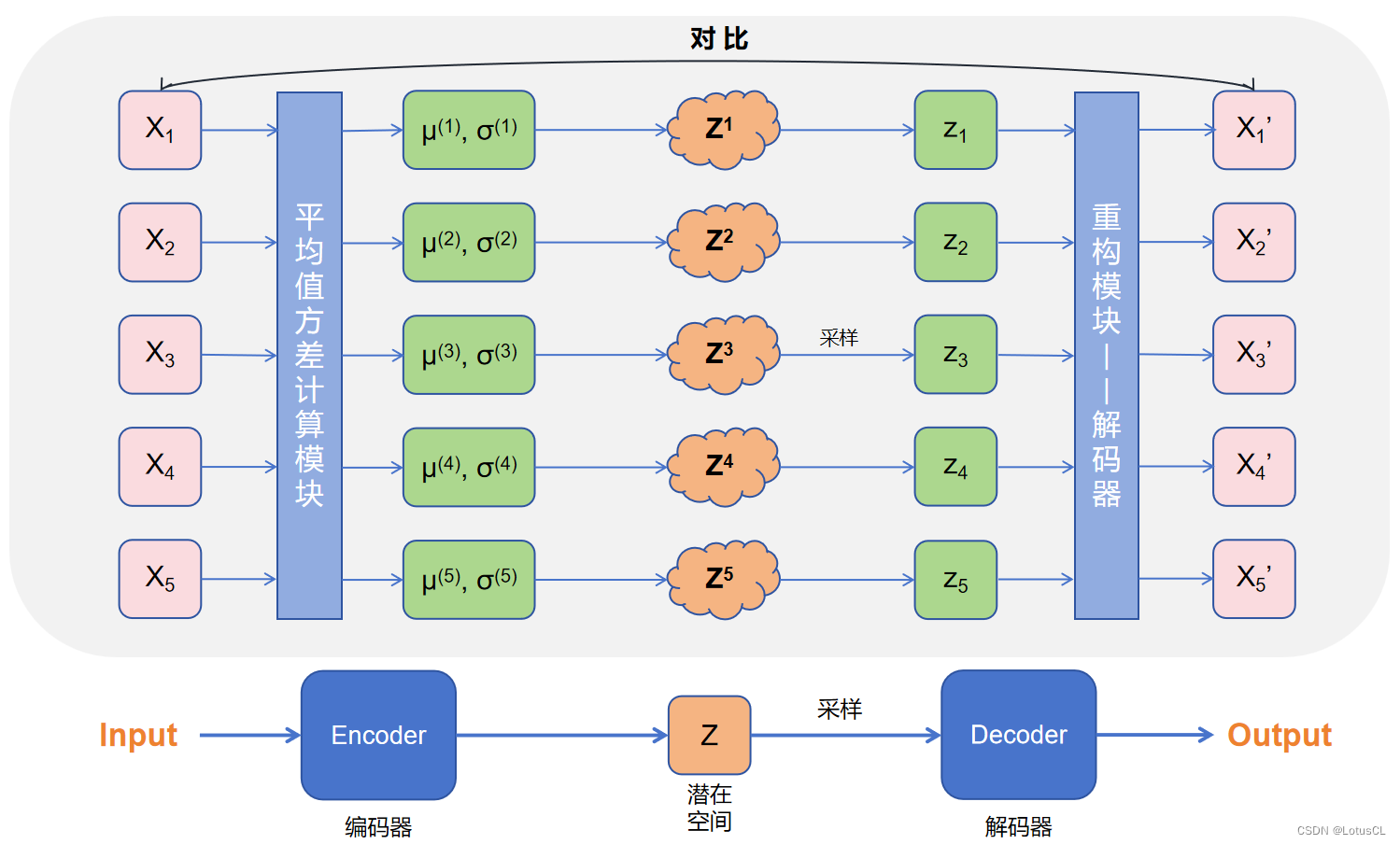
如图,首先他将一整个数据进行离散化各自计算它们的高斯分布特征
这里需要约束他们让他们强制符合正态分布
这个公式保证VAE对隐变量z施加的先验分布,假设其服从多维标准正态分布(均值为 0,协方差为单位矩阵)让概率生成更加精准。
在你得出正态分布之后他会进入Z的隐空间再进行采样进入decoder。此时decoder使用
在这里,我们的$\mu_\phi(x)$和$\phi(x)^2$是从encoder传过来的,decoder用这个重建概率分布并进行采样。
但是仅仅学习分布还不够,我们还要加强他的鲁棒性,这时候我们的老炼丹师们都会想到数据增强里面的添加噪声。没错,我们的研究者们也是这么想的
将随机采样过程分解为确定性变换和噪声注入,因为正态分布本身是$\mathcal{N}(z | 0, I)$的,那我从固定分布 (\mathcal{N}(0, I)) 采样噪声 (\epsilon)不就好了,然后还进行缩放和平移。保证了过程可微分,允许通过梯度下降优化编码器参数 (\phi)
最后再进行一次约束,因为你需要把结果和最开始进行对比,所以你需要比较先验与后验的区别。
衡量近似后验 (q_\phi(z|x)) 与先验 (p(z)) 的差异。优化目标:最小化KL散度,强制编码器生成的隐变量接近标准正态分布。
最重要的优化函数是什么呢?
以及总公式
吼吼吼,变分下界来喽,他最大化重构概率(左项),同时约束隐变量分布接近先验(右项)
详细解释一下吧,左边的是重构部分(也就是公式1),右边是正则部分(也就是上一个公式),左边是测量到底模型能否按照根据隐变量 z 准确还原输入 x ,也就是衡量decoder能力。
正则化就跟我之前说的一样,最小化编码器输出的隐变量分布 (q_\phi(z|x)) 与预设先验分布 (p(z))(如标准正态分布 (\mathcal{N}(0, I)))的差异,使隐空间具备结构化和泛化能力。也就是优化encoder能力。
通俗一点就是重构项:要求每本书(输入 x)都能被精确编码为条形码(隐变量 z),且能通过条形码完全还原书的内容。
正则化项:要求条形码的编码方式必须遵循特定规则(如正态分布),确保图书馆管理员(解码器)能根据随机生成的条形码创造合理的新书。
由此我们算是完整过了一遍模型数学基础了。